Programmieren 1 für Games
- Hauptseite
- [ ] Verlinkung zu einzelnen Themen
- [x] Einführung (“Programmieren”, “C und C++”, “Das erste Programm”)
- [x] Elementare Datentypen (“int”, “float”, “bool”, “char”, “string”)
- [x] Arithmetische Operatoren
- [x] Tipps und Tricks mit der IDE -> unwichtig, da Visual Studio spezifisch
- [ ] Ein- und Ausgabe aus der Konsole
- [ ] Kontrollstrukturen
- [ ] Arrays
- [ ] Funktionen
- [ ] Zufallszahlen
- [ ] Zeiger und Referenzen
- [ ] Namensbereiche
- [ ] OOP
- [ ] Dynamische Speicherreservierung
- [ ] Aufzählungstyp
- [ ] Makros und Konstanten
- [ ] Zeit
- [ ] OOP - Konstante Objekte und Standardmethoden
- [ ] OOP - Vererbung
- [ ] Datensätze mit struct
- [ ] Arbeiten mit Dateien
- [ ] Bibliotheken
- [ ] Container - Vektor
- [ ] Polymorphie
- [ ] Typumwandlung (Datentypen und Klassen)
Kompetenzen
- Arbeiten mit einer Integrated Development Environment (IDE) und Präprozessor, Compiler und Linker in dieser kennen und anwenden können. Erweitert wird dies durch
- Grundlegende und strukturierte Datentypen,
- Kontrollstrukturen und logische Bedingungen,
- Felder, **Zeiger und dynamische Speichermanagement, sowie
- Funktionen und Prozeduren aus C. Auch soll das
- Objektorientierte Programmieren mit den Grundlegenden Konzepten aus C++ gekannt und angewendet werden.
- Modulare Programme schreiben und die “toolchain” der Entwicklung von C/C++ Programmen und Biblioheken verstehen und anwenden.
Lernergebnis
Am Ende des Semesters sollen die Stunden in der Lage sein mit der IDE zu arbeiten, d.h. sie programmieren, übersetzen den Code und Fehler werden behoben. Durch ständiges Üben ist es ihnen möglich Abhilfe für kleine Probleme der realen Welt mit strukturierten, modularen Programmen zu lösen.
Einführung
Programmierung ist nötig, da der Computer bzw. der Prozessor nur exakt formulierte Aufgabenstellungen ausführen kann. Dieser ist im Resultat aber weitaus effizierter als der Mensch z.B. Ausrechnen von komplizierten Formeln.
Das Schreiben des Programms muss trotzdem der Mensch unternehmen, auch wenn sog. KIs (Künstliche Intelligenz) immer besser werden, wodurch sie das immer stärker übernehmen.
Problem ist nun leider, dass zwischen Mensch und Maschine eine Sprachbarriere ist. Wir Menschen sprechen die natürlich Sprache, welche während dem Gesprächs die Fähigkeit hat Informationen zu interpretieren und dadurch Ironie etc. versteht. Der Computer spricht in der Maschinensprache, welche binören Codes ließt und dadurch nur 0en und 1er versteht.
Als Schnittstelle der beiden Parteien bieten sich Programmiersprachen an, da diese für Beide verständlich sind und dadurch einen guten Kompromiss darstellen.
Dadurch entsteht folgendes Vorgehen:
- Der Mensch übersetzt sein Problem der realen Welt in eine Programmiersprache
- Speziele Übersetzungsprogramme wandeln diese in eine verständliche Maschinensprache um
- Der Computer kann nun die Anweisungen ausführen
Anweisungen / Befehle
Anweisungen und Befehle sind unterschiedlich von Programmiersprache zu Programmiersprache, aber grundlegende Konzepte beliben identisch.
Zuweisung:
- Initialisierung: Name = EinTollerName
- Zuweisung: EinJahr = 1980 + EinPaarJahreMehr
Kontrollstukturen:
- Bedingte Anweisungen: wenn dass eintrifft … dann mache … sonst tu … (if - else)
- Blockanweisungen: mache solange … bis … eintritt (Schleifen)
Prozedur-/Funktionsaufrufe:
- SpieleMusik(Titelnummer)
- Unterschied zwischen Prozedur und Funktion (geminersamer Begruff in der OOP ist Methode) nicht klar definiert, aber eine mögliche Unterscheidung ist, ob ein Rückgabewert vorliegt (Funktion) oder nicht (Prozedur).
Programmiersprachen
Große Anzahl von Programmiersprachen, welche nach bestimmten Kriterien unterscheidbar sind:
- Kompilierte vs. Interpretierte Spachen -> Portabilität/Geschwindigkeit/…
- Programmierparadigmen -> Programmierstil, den die Sprache unterstützt (oder auch nicht)
- Datentypeigenschaften -> Definition/Kombination von Datentypen
- Nähe zur Maschinensprache -> High or low level Sprachen
Kompilierte vs. Interpretierte Sprachen
Kompilierte Sprachen:
- werden in sogg. nativen Sprachen (Maschinensprache) des Zielsystems mithilfe des sogg. Compilers übersetzt.
- Sind i.d.R. *sehr schnell ausführbare Programme, müssen aber
- für jeden Zielsystem und bei jeder Codebearbeitung neu kompiliert (übersetzt) werden.
- “Verschlüsselung” des Codes in gewisser Weise.
- z.B. C, C++
Interpretierte Sprachen:
- werden von einen anderem Programm, dem sogg. Interpreter nach und nach gelesen und ausgeführt, sind dadurch
- besser portierbar (übertragbar) auf andere Systeme, soweit ein anderer Interpreter für dieses System existiert, führen aber durch gleichzeitige lesen und ausführen zu einem
- wesentlich langsameren Ausführen des Programmes.
- z.B. MATLAB, BASIC, PHP, Perl
Just-in-Time kompilierte Sprachen (Zwischensprache):
- sind eine Kombination aus Beiden anderen und will dadurch deren Vor- und Nachteile ausgleichen
- Code wird zum Zeitpunkt des Bedarfs ausgeführt.
Portabilität:
- Jeder Prozessor/Zielsystem hat seine eigene Maschinensprache
- Portabilität beschreibt die Eigenschaft eines Programms auf vielen verschiedenen Zielsystemen eingesetzt werden zu können.
High vs. Low Level Sprachen
Das Level beschreibt die Nähe/Ähnlichkeit zur Maschinensprache des Systems:
Je ähnlicher, desto lower:
- Anwendung: Treiberprogrammierung, hardwarenahe Programmierung
- Ziel ist es jede Funktion einer bestimmten Hardware höchsteffizient ansprechen zu können
Je abstrakter/universeller/für den Menschen besser lesbarer, desto “higher”:
- Ziel ist es universelle Aufgaben einfach und schnell umsetzbar zu machen
- “Programmieren ist für jedermann”
=> Programmierer muss selbst entscheiden, welche Sprache er für sein Projekt benötigt:
- Ein Computerspiel wird eher in einer high-level Sprache geschrieben, während aber
- der Gamecontroller für das Spiel eher in ein einer low-level Sprache geschreiben wird.
Assembler
ist die erste Programmiersprache und ähnelt der Maschinensprache, ist aber für den Menschen noch lesbar. Ein Veranschaulichung des Codes bietet dieser Übersetzer von C++ in Assembler. Dies ist auch Thema in der Vorlesung IT-Systeme - Assemblerprgrammierung.
Kommunikationsprotokolle
Auch wenn der Mensch mit dem Computer mit Programmiersprachen kommuniziert, heißt das nicht das Computer gegenseitig das Gleiche machen. Sie benutzen Kommunikationsprotokolle, wie z.B. TCP, IP, HTTP, FTP, SMTP, …
Syntax und Semantik
Syntax:
- Definiert das Erscheinungsbild des Quelltextes/Codes, d.h. ist ein Regelwerk (Grammatik)
- Aufgabe: Welche Wörter und Wortfolgen sind gültig um einen funktioniereden Code zu schreiben?
Semanik:
- Definiert die Bedeutung von Zeichen-/Wortfolgen
- Aufgabe: Was bedeuten die Wörter und Wortfolgen bzw. welche Wirkung haben Sie in meinem Quellcode?
Game-Engineering
Mit Game-Engine kommt man alleine schon recht weit, indem man “Featuren zusammenklickt”, aber: die eigene Innovation wird dadurch eingeschränkt durch die Fähigkeit der Engine.
Viele Entwicklungsstudios entwickeln deshalb (und aus anderen Gründen) ihr eigene Engines.
Durch die eigenen Programmierkenntnisse können so spezielle Grafikeffekte, Interfaces/Controler, Charaktere (KI) und vieles mehr entwickelt und benutzt werden.
Außerdem werden neue Spielansätze und Anforderungen von herkömmlichen Engines noch gar nicht unterstützt. z.B. Kompatibilität zu VR, AR, …
C und C++
C
wurde von Dennis Ritchie zwischen 1969-1973 in den Bell Laboratories, NJ, USA entwickelt, um das neue Betriebsystem UNIX zu programmieren und diente als Vorbild für andere von C insperierte Sprachen. C ist eine prozedurale Sprache.
C++
wurde von Bjarne Stroustrup und seinen Mitarbeitern in den Bell Laboratories (AT & T, USA) entwickelt, um effizienter implementieren zu können. Frühe Versionen, wie “C mit Klassen”, gibt es seit 1980. Ab 1989 wurde mit der Standardisierung von C++ begonnen, um Sprachdialekte zu vermeiden, so wurde dann 1998 der ISO Standard CD 14882 für C++ verabschiedet.
Aus dem Namen ist schon ersichtlich, dass C++ aus C entstand, dabei wurden sogar die kompletten Eigenschaften übernommen.
Eigenschaften von C:
- Universell einsetzbare, modulare Programme
- Effiziente, maschinennahe Programmierung
- Übertragbarkeit auf verschiedene Rechner (Portabilität)
Eigenschaften von C++:
- OOP: Objektorientierte Programmierung
Warum C und C++
- beinhaltet alle wichtigen Programmierkonzepte (insbesondere OOP) und ist eine gute Basis für den Einstueg in weitere Programmiersprachen
- Schult die Sensibilität mit dem Umgang von Ressourcen (Speicher und Rechenpower), d.h. man kümmert sich z.B. um den verwendeten Speicher selbst
- Sehr weit verbreitet -> leichter Einstieg, viele Bibliotheken, Unmengen an Ressourcen, größte Programmiersprache 2016 (Spectrum IEEE)
- Native Programmiersprache, d.h. dirkete Übersetzung des Quellcodes in Maschinensprache und damit sehr schnell => echtzeitkritische Anwendungen, Verarbeitung großer Daten
- Ermöglicht viele verschiedene Programmierstile(Programmierparadigmen) -> Prozedural, Generisch, OOP, …
- Hot eine hohe Portabilität da weit verbreitet und für beinahe jedes Zielsystem Compiler vorhanden sind
- Neue C++ Codes sind kompatibel mit ggf. älteren C-Codes
- Didaktische Gründe -> C veranschaulicht Konzepte von prozeduralen Programmiersprachen, C++ veranschaulicht die Vorzüge von objektorientierten Programmiersprachen
- Weite Verbreitung in anderen Anwendungsbereiechen z.B. Medizintechnik
- Schnittstelle zu den Grafik-APIs für die 3D Computergrafik, zB. OpenGL, DirectX
Versionen und Standardisierung
- Gegen das “Wildwuchs” von Sprachdialekten -> Anmerkung: Deutsche Sprache ist nicht standardisiert z.B. Brötchen vs. Semmel
- Beteiligte Organisationen zu Entwicklung des Standard ist ANSI (American National Standard Institute) und ISO (Internationale Ordnung für Normung)
- Neuste C Version: C11
- Neuste C++ Version: C++14
Erstes Programm
Zunächst wird eine Integrated Development Environment (IDE) benötigt, da viele Funktionen für den Entwickler bereitstellt und somit die Arbeit an den Code angenehmer macht. Wichtige Funktionen sind Projekte aufsetzen, Quellcodeeditor, Fehlersuche, Kompilieren und Linken, etc.
Das Programm wird aus mehreren Dateien zusammengesetzt**:
- Erstellen einer Quelldatei .cpp, indem der Quellcode geschrieben ist. Dabei werden Header-Dateien .h hinzugefügt.
- Es entsteht eine Objektdatei .obj, welche durch Bibliotheken .lib/.dll erweitert wird. Die Standardbibliothek zählt auch dazu.
- Am Ende steht eine ausführbare Datei .exe bereit.
Ein simples Programm für den Einstieg ist das sog. Hello World!-Projekt.
Hello World
“Hello World” gibt einen kurzen Einblick in viele Funktionen einer Programmiersprache, da viele simple, aber allgemein wichtige Anweisungen aufgeführt werden.
#include <iostream>
using namespace std;
int main(){
std::cout << "Hello World!" << endl; //endl gehört auch zu std
cout << "Oder auch: Hallo Welt!\n";
return 0;
}
Präprozessordirektive: z.B. #include <header> oder _#include “header”
Diese wird eingeleitet durch ein # und wird ausgeführt am Anfang der Kompilierphase erzeugt noch keine Objektdatei, sondern bündelt Informationen und bereitet diese vor.
Das *include+ gibt an, dass Dateien in das Projekt bzw. den Quellcode ingebunden werden. Allgemein gesagt: <header> bindet Standardbibliotheken ein und “header” eigen erstelle Dateien. Mehr dazu (sehr viel) später.
iostream: Ist zuständig für die Ein und Ausgabe auf der Konsole.
int main: Aufruf der Hauptfunktion.
Die Hauptfunktion ist Pflicht für jedes Programm, da diese Funktionen und Anweisung aufruft. Man könnte sie auch einen roten Pfad nennen, da hier alles zusammenführt und nach der Reihe ausgeführt werden. Das return 0; zeigt, dass das Programm den Exit-Code zurückgibt und ist ebenfalls Notwendigfür alle Funktionen mit einem Rückgabewert. Mehr dazu unter “Funktionen”.
Funktionsblock: { inhalt }
In dem Funktionblock befindet sich alles, was das Programm berechnen/ausführen soll.
Kommentare //Inhalt oder /* Inhalt */
Kommentare werden vom Compiler ignoriert und können dadurch benutzt werden, den Code übersichtlicher zu machen. Dies ist besonders praktisch für das Verständnis anderer Personen, da diese den Code dadurch schneller verstehen. Den es gilt: Teamwork OP!
// wird alles ignoriert -> Einzeiler-Kommentar
/* -> Beginn eines Kommentarblocks */ -> Ende eines Kommentarblocks
Anweisungen enden immer mit einem Semicolon/Strichpunkt ;
Konsolenausgabe:
Da wir iostream eingebunden haben, können wir auf der Konsole des Computers schreiben und auslesen.
std:: kennzeichnet den Namensbereich, indem cout und endl definiert sind. Da wir using namespace std; angegeben haben, muss std:: nicht benutzt werden.
cout (console output) ist eine Funktion der Standardbibliothek, die die Ausgabe auf der Konsole ermöglicht.
” Inhalt “ ist ein String und dessen Inhalt wird nach cout « ausgegeben.
« ist ein Operator, der die Zeichen in den sogg. outputstream schiebt.
endl (end of line) ist ebenfalls eine Funktion der Standardbibltiothek und ruft einen Zeilenvorschub hervor. Alternativ kann in dem String “\n” eingefügt werden, welcher den gleichen Effekt erzeugt.
Elementare Datentypen - Integer und Strings
Ein wichtiger Bestandteil jedes Programmes sind Variablen. In diesen können verschiedene Werte gespeichert und wieder benutzt werden. Um Variablen zu speichern, müssen wir davor noch angeben, wie viel Speicher sie brauchen. Das ist abhängig von der Art des Wertes - also Zahl oder Buchstabe/n - und dem Wertebereich.
Deklaration und Defintion
Deklaration: Wir legen Datentyp und Name fest, dadurch kann der Compiler Speicher reservieren, aber die Variable hat zurzeit noch keinen festgelegten Wert.
Syntax: Datentyp Variablenname;
Namensregeln:
- Anfang mit a-z, A-Z oder _
- Danach darf a-z, A-Z, _ und Zahlen benutzt werden
- Bereits reservierte Wörter wie continue können nicht benutzt werden
- Unterscheidung von Groß- und Kleinschreibung
Empfehlung für Namensregeln:
Allgemein sollte man darauf achten, dass man Variablen schnell verständliche Namen gibt. Am Besten auch gleich einen Kommentar anhängen, um zu erklären, was die Aufgabe der Variable ist. Es haben sich im Laufe der Zeit verschiedene Regeln zur Namensgebung entwickelt:
- Ungarische Notatiion:
- Datentyp wird in den Namen übernommen, z.B. int iNumberOfPlayers oder int i_NumberOfPlayer
- Trennung von Wörter in den Variablen über Großschreibung des Ersten Buchstaben des Wortes
- Teamarbeit:
- am besten in Englisch
- Programming Guidelines festlegen -> Format der Namesgebung, Formatierung des Codes, Kommentarregeln, etc.
- lokale Codebereiche:
- i oder j für Schleifenindizien
- r, g, b, a für Farben und Transparenz
- x, y, z für 2D/3D-Koordinaten
Anmerkung: Benutzen wir die Variable jetzt, dann wird ein zufälliger Wert ausgegeben, falls der Compiler das überhaupt zulässt.
Defintion: Nun wird der Variablen ein Wert zugewiesen. Natürlich muss davor aber erstmal ein Datentyp festgelegt sein.
Syntax: Variablenname = einWert;
Es ist möglich Defintion und Deklaration zu kombinieren.
int eineZahl = 44; //Definition und Deklaration
int eineAndereZahl(21);
int x_pos, y_pos, z_pos; //Deklaration von drei Variablen
x_pos, y_pos, z_pos = 5; //Defintion durch verkettete Wertezuweisung.
//Aber:
int Zahl1, Zahl2, Zahl3 = 3; //Nur Zahl3 wird 3 zugewiesen
int nochEineAndereZahl(22), eineGanzAndereZahl(42);
Integer - Ganze Zahlen
I.d.R. hat ein Integer 4 Byte (16 Bits) Speicherplatz. Integer können aber verschiedene Formen annehmen, welche diese Tabelle darstellen soll:
| Datentyp | Speicherplatz (Byte) | Wertebereich | Notiz |
|---|---|---|---|
| bool | 1 | 1,0 bzw. true, false | Sehr viel Speicher für 2 Ziffern |
| char | 1 | -128, +127 | Benutzung für ASCII |
| short | 2 | -32.768, +32.767 | Hälfte von Integer |
| integer | 4 | -2.147.483.648, +2.147.483.647 | Alternativer Name: long |
| long long | 8 | -9.223.372.036.854.775.808, +9.223.372.036.854.775.807 | Doppeltes von Integer |
Mit Ausnahme von bool kann an jeden Datentyp noch ein unsigned (ohne Vorzeichen) angehängt werden, um den Wertebereich auf 0 zu verschieben. z.B. unsigned short -> 0, 65.535
Für die Umrechnung von Dezimalzahlen in Binärzahlen solle ein Blick in die Vorlesung “Einführung in die Informatik” gemacht werden.
Overflow
Definition: Der Absolutbetrag des Ergebnisses einer Berechnung oder des Wertes einer Wertzuweisung ist außerhalb des Wertebereichs des Zieldatentyps.
Problem: char hat nur einen Byte zur Verfügung und kann dadurch nicht mehr Zahlen außerhalb des Wertebereichs (z.B. -129) anzeigen.
Lösungsansätze: Modifizierer unsigned und signed
z.B. signed char:
127 -> 0111 1111 128 -> 1000 0000, aber: 1st bit gibt Vorzeichen an: also = -128 129 -> 1000 0001, aber: … = -127 …
unsigned char:
127 -> 0111 1111 128 -> 1000 0000 … 255 -> 1111 1111 256 -> 1 0000 0000 -> Nicht mehr Anzeigbar mit char
Ohne Angabe eines Modifizierers ist der Datentyp mit Vorzeichen. Man sollte allgemein als Entwickler überblick über die Werte seiner Variablen behalten.
Mögliche Overflow-Gefahren sind:
- Eine Variable wird ständig verändert z.B. Spielzeit, gefahrene Schüsse
- Externe Daten werden nicht korrekt/sauber gelesen, wenn z.B. Farbtiefe falsch gelesen wird
Ein weiteres Problem: Der Integer-Wertebereich ist System-individuell:
- abhängig von dem Datenmodell des Prozessors und
- Prozessorarchitektur des jeweiligen Betriebsystems
Hilfestellung 1: Die Funktion sizeof() gibt die Anzahl der Bytes aus
cout << "long: " << sizeof(long) << "Bytes" << endl;
Hilfestellung 2: Die Konstanten in climits geben Wertebereiche zurück
cout << "Wertebereich - long long: " << LLONG_MIN << ", " << LLONG_MAX << endl;
Float - Gleichkommazahlen
| Datentyp | Speicherplatz (Byte) | Wertebereich | Genauigkeit(Stellen) |
|---|---|---|---|
| Float | 4 | ±3.4E+38 | 6 |
| Double | 8 | ±1.7E+308 | 15 |
| Long Double | 10 | ±1.1E+4932 | 19 |
Anmerkung zu Genauigkeit: D.h. das insgesamt so viele Stellen angezeigt werden können
float eineZahl = 20.0001f;
cout << eineZahl << endl; //20.0001
eineZahl = 20.00009f;
cout << eineZahl << endl; //20.0001, 7 Stellen, aber es werden nur 6 angezeigt
Underflow
Bei Gleitkommazahlen kann es vorkommen, dass der wahre Wert einer Berechnung zu klein ist (zu viele Nachkommastellen) um durch Datentypen dargestellt zu werden.
Praktischerweise können wir ebenfalls sizeof() und climits benutzen, um Speicherplatz und Wertebereich zu überprüfen.
#include <climits> //oder <cfloat>
float fUnderflow = DBL_MIN; //Kleinster double Wert wird einem Float zugewiesen
cout << "DBL_MIN: " << DBL_MIN << endl; //2.22507e-308
cout << "fUnderflow: " << fUnderflow << endl; //0 -> Underflow
Konstanten
Eine Konstante ist eine Zahl, ein boolesches Schlüsselwort, ein zeichen oder eine Zeichenkette/String.
Ganzzzahlige nummerische Konstanten
sind i.d.R. von Typ int. Sollte der Wert zu groß für den Datentyp sein, so wird diese erweitert, d.h. sie wird zu long, und dann zu long long.
Den Datentyp ist auch erkennbar durch die Schreibweise. Beispiele:
- 12UL/12ul -> unsigned long
- 19L/19l -> long
- 15U/15u -> unsigned int
- …
Zahlen können auch in verschiedenen Zahlensystemen angezeigt werden:
- Dezimal -> beginnt mit Ziffern von 1 bis 9 z.B. 120
- Octal -> beginnt mit einer 0 z.B. 0120
- Hexadezimal -> beginnt mit 0x oder 0X z.B. 0x120
Möchte man Konstanten in andere Zahlensysteme umwandeln, so kann man die Operatoren oct, hex und dec in Kombination mit dem Outputstream « benutzen.
cout << "16 in Hexadezimal: " << hex << 16 << endl;
Gleitpunktkonstanten
sind Standardmäßig von Typ double können aber mit als
- float mit dem postfix f/F (1.2f) oder
- long mit dem postfix l/L (1.2l) angegeben werden.
Konstante Objekte
Konstanter Datentyp
const int eineZahl = 44;
Durch das Schlüsselwort const vor dem Datentyp wird diese als Konstante deklariert. Folglich ist diese nicht überschreibar, da der Compiler sie schützt. Anwendung finden sie z.B. bei der maximalen Anzahl von Spielern.
Präprozessor
Syntax: #define TEXZERSETZUNG Inhalt
#define EINE_ZAHL 44
Durch das Schlüsselwort define hinter der Präprossessordirektive, werden alle Textstellen hinter dem #define mit dem Inhalt ausgetauscht. GROSSSCHREIBUNG hat sich als Erkennungsmerkmal eingebürgert.
Datentyp bool
- 0 bzw. false und 1 bzw. true
- Wichtigster Datentyp zur
- Kontrolle des Programmflusses
- Implementierung von Logik
- Kann in Kombination mit Boole’schen Operatoren benutzt werden
bool updateReady = true;
Datentyp char
Zwar können char Variablen auch benutzt werden, um Zahlen zu speichern, ist es eigt. gedacht diese für einzelne Zeichen zu benutzen. Um diese Darzustellen, gibt es verschiedene Zeichensätze:
- ASCII: 7-bit Datensatz, 128 Zeichen
- ANSI: 8-bit Datensatz, 256 Zeichen (enthält ASCII)
- UNICODE: ≈130.000 Zeichen
Möchte man nun ein Buchstabe in einer Variable speichern, so muss dieser in ’ ‘ gesetzt werden.
char BuchstabeA = 'A';
Letztendlich ist die Zielausgabeeinheit - i.d.R. der Bildschirm - zuständig für die korrekte Ausgabe.
ASCII
- American Standard Code for Information Interchange
- Zeichenkodierung im englischsprachigen Raum
- [0, 31] -> 32 Steuerzeichen
- [32, 127] -> 96 druckbare Zeichen, also das lateinische Alphabet in Groß- und Kleinschreibung, zehn arabische Ziffern, Interpunktionszeichen und Sonderzeichen
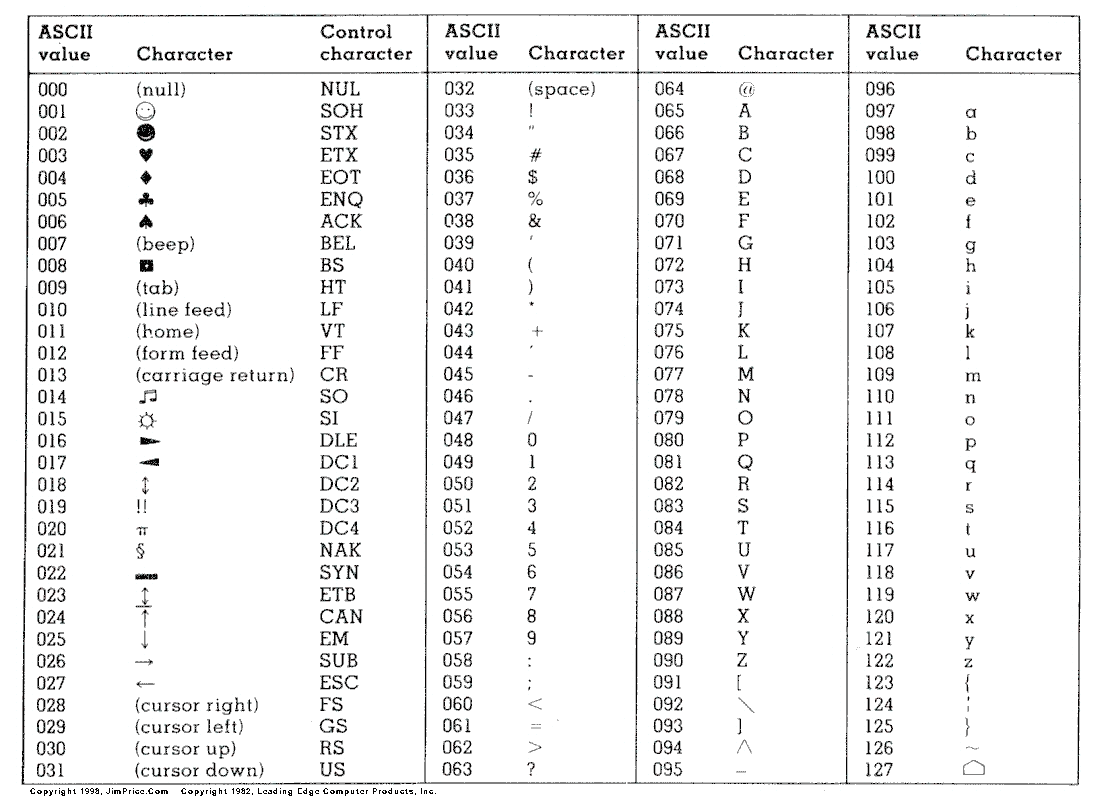
ANSI
Erweiterung der ASCII-Tabelle um einen Bit. Nun sind z.B. deutsche Umlaute darstellbar.
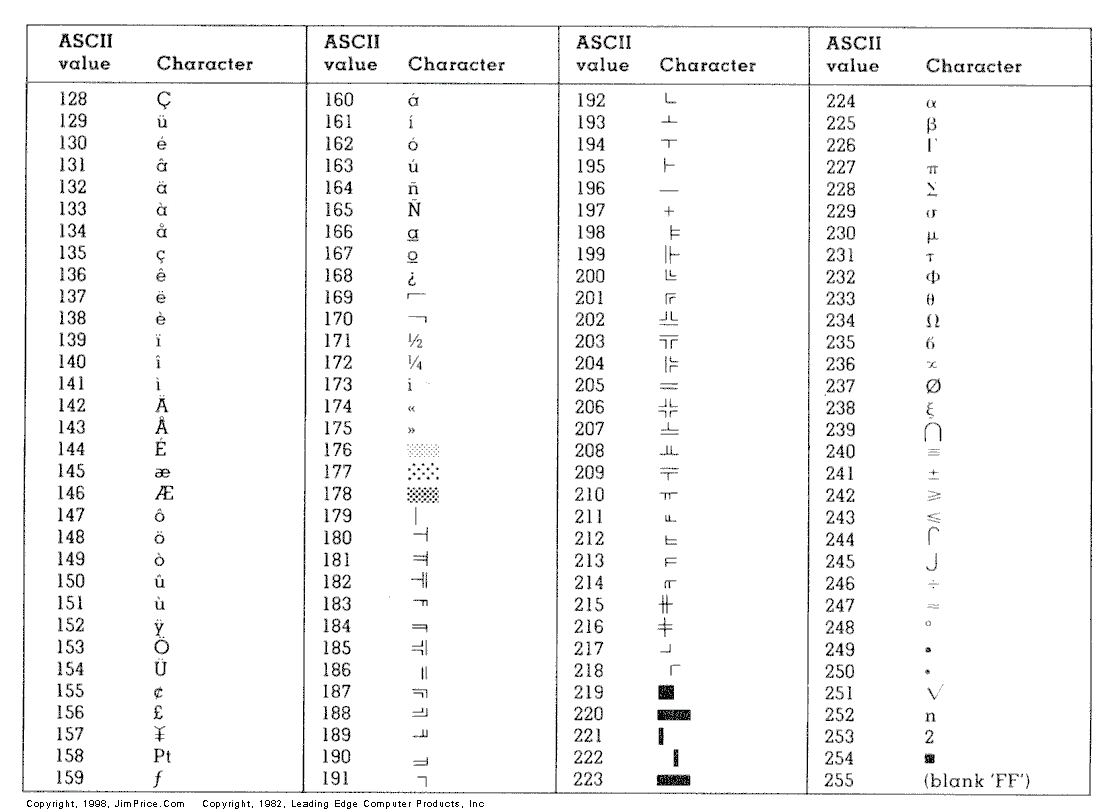
char einCoolesZeichen = 0xCE;gm
### Unicode
Da char nur 8 Bit hat, kann der Unicode nicht mehr dargestellt werden. Deswegen müssen alternative Datentypen her: **char16_t** (2 Byte), **char32_t** (4 Byte) (*wchar_t* ist veraltet).
## Datentyp string
Strings sind **Zeichenketten**, welche das Arbeiten viel einfacher machen als mit chars. Um diese anzugeben, werden **" "** benutzt.
Die Zeichenkette endet inter immer mit dem **Stringendezeichen \0**, welches 1 Byte benötigt. Folglich ergibt dies für den **Speicherbedarf**: **Anzahl der Zeichen + 1**.
I.d.R. sind strings im **iostream** integriert, aber es kann alternativ **<string>** eingebunden werden.
```c++
#include <iostream> //<string>
unsing namespace std;
string einName = "Hans"; //std::string
cout << "Hallo ich bin " << einName << "." << endl;
Umlaute
Umlaue müssen aus dem ANSI Zeichesatz entnommen werden, dies kann entweder über einer Zuweisung des Zeichencodes an einem char passieren, oder als hex code an einer Stringkonstante
| Zeichen | Hex |
|---|---|
| ä | 84 |
| Ä | 8E |
| ö | 94 |
| Ö | 99 |
| ü | 81 |
| Ü | 9A |
| ß | E1 |
//cout << Üben << endl; //geht nicht
cout << \x9aben << endl; //Üben
char UE = 9a;
cout << UE << "ben" << endl; //Üben
Funktionen mit Strings
Ein string ist eine Klasse, in welcher verschiedene Funktionen integriert wurden. Mehr über Klassen in der OOP.
TODO: Verlinkung OOP
Suchen: string.find() -> Gibt (Start-)Position einer gesuchten Zeichens/-kette zurück.
Vier Varianten:
size_t find (const string& str, size_t pos = 0) const; //2 Parameter, wovon nur der erste angegeben werden muss
size_t find (const char* s, size_t pos = 0) const; //Same here
size_t find (const c, size_t pos = 0) const; //Again, same here
size_t find (const char* s, size_t pos, size_t n) const; //3 Parameter
- str -> gesuchter String
- char -> Suche ein Array von char
- c -> einzelnder char
- pos -> Start der Suchposition
- n -> Länge der gesuchten Zeichenkette
string stringA = "Ich bin ein String!";
string stringB = "String";
size_t SucheString = stringA.find(stringB); //Suche "String" ab 0ter Stelle -> Zahl als Ergebnis
string::npos: npos ist eine Konstante für den höchsten Wert von size_t. Nutzbarkeit findet diese für die Abfrage einer erfolgreichen Suche.
if(SucheString != string::npos){ //Verzweigung nur wenn StringB in StringA gefunden wurde
cout << stringB << " wurde an der " << SucheString << "ten Stelle gefunden." << endl;
}
Erweiterung von Strings: Anhängen weiterer Zeichen an einen String
- + Operator
- .append()
- .push_back()
stringC = "Zeichenkette";
stringA += "Ich ";
stringA.append("bin ");
stringA.push_back("eine ");
stringA.append(stringC);
stringA += "! Liebe ";
stringA.push_back("mich!!!");
cout << stringA << endl; //Ich bin ein String! Ich bin eine Zeichenkette! Liebe mich!!!
Länge: string.length() -> gibt Länge des Strings als Zahl zurück.
stringA.length; //60
Ersetzen: string.replace() -> ersetze eine Anzahl von Zeichen mit anderen
-
- Parameter -> Startposition
-
- Parameter -> Anzahl der zu ersetzenden Zeichen
-
- Parameter -> ein neuer String
stringA.replace(stringA.find(stringC) + stringC.length() + 2, 13, "Ich bin praktisch!");
cout << stringA << endl; //Ich bin ein String! Ich bin eine Zeichenkette! Ich bin praktisch!
Einfügen: string.insert() -> Füge einen String an einer bestimmten Position ein.
-
- Parameter: Startposition
-
- Parameter: Einzufügender String
stringA.insert(stringA.find(stringB) + stringB.length() + 2, "D.h. ");
cout << stringA << endl; //Ich bin ein String! D.h. Ich bin eine Zeichenkette! Ich bin praktisch!
Teilstring: string.substr() -> Nimm ein Teil von einem String
-
- Parameter: Startposition
-
- Parameter: Endposition
string stringD = stringA.substr(stringA.find(stringB) + stringB.length() + 2, stringA.find(StringC));
cout << stringD << endl; //D.h. Ich bin eine Zeichenkette!
Natürlich gibt es noch viele weitere Funktionen von strings. Mehr dazu auf cplusplus.
Umwandlung: Zahlen <-> String:
string to:
- stoi -> int
- stoul -> unsigned int
- stol -> long
- stoll -> long long
- stoull -> unsigned long long
- stod -> double
- stof -> float
- stold -> long double
Parameter: ein String
Alternative Möglichkeit: atoi, etc. aber diese möchten ein char-Array
number to string: to_string(val), val = number
int eineZahl = 42;
string einString = to_string(eineZahl); //42
int eineAndereZahl = stoi(einString); //42
Arithmetische Operatoren
- Binären Operatoren -> 2 Operanden
- Unärer Operatoren -> 1 Operand
- Zusammengesetze Kombinationen
- Vergleichsoperatoren
- Boole’sche Operatoren -> Kontrolle von Programmen
Hinweis
Hinter jeder Operation muss hinterfragt werden, ob der Datentyp passt, d.h. wenn als Ergebnis einer Operation eine Gleitpunktzahl entsteht, muss der Datentyp der Variable auch passen.
Variable können auch zum Rechnen benutzt werden.
Binäre arithmetische Operatoren
| Linker Operand | Operator | Rechter Operand |
|---|---|---|
| A | + | B |
| Operator | Bedeutung | Beispiel |
|---|---|---|
| + | Addition | 2 + 6 = 8 |
| - | Subtraktion | 2 - 6 = -4 |
| * | Mutiplikation | 2 * 6 = 12 |
| / | Division | 2 / 6 = 0.33333 |
| % | Modulodivision | 2 % 6 = 2 |
Division
Wie oben bereits erwähnt muss ein entsprechende Datentyp angegeben werden, damit man ein gewünschtes Ergebnis erzielt.
- Division mit ganzzahligen Operanden -> ganzzahliges Ergebnis (abgerundet)
- Mind. ein Operand ist eine Gleitkommazahl -> Ergebnis als Gleitkommazahl
- Erinnerung: .f um aus ganze Zahlen Gleitkommazahlen zu machen.
int var1 = 2 / 6; //= 0
float var2 = 2 / 6: //= 2.00000
int var3 = 2.f / 6; //= 0
float var4 = 2 / 6.f; //= 0.33333
//Am besten immer .f hinter allen ganzzahligen Zahlen bei Gleitkommazahlen-Berechnungen setzen!
Modulodivision
Nur anwendbar auf ganzzahilge Operanden.
Beispiel: x % 4 = erg
| x | erg |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 0 |
| 5 | 1 |
| 6 | 2 |
| 7 | 3 |
| 8 | 0 |
| 9 | 1 |
| 10 | 2 |
Anwendung: Erzeugung von Zufallszahlen in einem bestimmten Wertebereich -> Thema später
Ausdrücke
Natürlich können wir auch mehrere Operanden und deren Operatoren kombinieren. Dabei gelten die üblichen Rechenregeln -> Punkt vor Strich, etc.
Eine übersicht welche Operatoren Priorität über andere haben wir zum Schluss des Kapitels gezeigt.
Unäre arithmetische Operatoren
| Operator | Bedeutung | Beispiel |
|---|---|---|
| + und - | Vorzeichenoperator | x = 5; y = -x; //y = -5 |
| ++ | Inkrementoperator | x = 2; x++; //x = 3 |
| – | Dekrementoperator | x = 2; x–; //x = 1 |
Inkrement- und Dekrementoperatoren
verändern den Wert um 1.
Unterscheidung zwischen:
- Präfix-Notation (i++):
- Benutzung des alten Wertes
- Erhöhung von i um 1
- Postfix-Notation (++i):
- Erhöhung von i um 1
- Benutzung des alten Wertes
int var1 = 2;
int var2 = var1++; //var2 = 2
int var3 = ++var1; //var3 = 4
Zusammengesetze Zuweisungen
Es besteht die Möglichkeit den Zuweisungsoperator “=” mit den binären Operatorn zu kombinieren.
-> +=, -=, *=, /=, %=
int var1 = 2;
var1 = var1 + var1; //var1 = 4
var1 += var1; //var1 = 8
Vergleichsoperatoren
| Operator | Bedeutung | Bespiel | Ergebnis |
|---|---|---|---|
| < | Kleiner | 4.5 < 5.623 | true |
| <= | Kleiner gleich | 2 <= 1.98 | false |
| > | Größer | ||
| >= | Größer gleich | ||
| == | Gleich | 2*2 == 5 | false |
| != | Ungleich | 2*2 != 5 | true |
Hinweis
Nicht die Zuweisung “=” mit dem Vergleichsoperator gleich “==” verwechseln!
Boole’sche Operatoren
Konjunktion &&
| && | 0 | 1 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
-> Das Monster hat unter 50% seiner HP und hat keine MP dann heilt es sich.
Disjunktion ||
| oder | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 1 |
-> Der Spieler ist verletzt oder setzt Block ein dann aktivieren sich die Invincibility-Frames.
Konjunktionen haben Priorität über Disjunktionen.
Negation !
| ! | |
|---|---|
| 0 | 1 |
| 1 | 0 |
-> Der Spieler ist nicht im Empfohlenen Levelbereich dann greifen die Monster nicht an.
Werden Boole’sche Operatoren in Kombination mit Integer/Float-Zahlen kombiniert, dann sind alle Zahlen >/< 0 -> 1 und 0 -> 0
Vorrang der Operatoren
| Prioriät | Operator |
|---|---|
| 9 | Postfix ++ |
| Postfix – | |
| 8 | ++ Präfix |
| – Präfix | |
| + Vorzeichen | |
| - Vorzeichen | |
| ! | |
| 7 | * |
| / | |
| % | |
| 6 | + |
| 5 | < |
| <= | |
| > | |
| >= | |
| 4 | == |
| != | |
| 3 | && |
| 2 | \mid\mid |
| 1 | = |
| *=, /=, +=, -=, |